
Edible mushroom classification using ML techniques.
Mushrooms are tasty.
In the dream of one day going out and forage mushrooms I want to have something with me to predict wether the mushroom I pick would try to kill me or not. So using my infinite wisdom I decided to build ML models to help me identify edible mushrooms instead of reading the government guidelines.

Some techniques being used:
-
This project explores multiple types of Naive Bayes models ranging from the default model to one that’s optimized using grid search CV to the counterintuitive but powerful Greedy Naive Bayes
-
This project also used a KNN classifier and optimized the number of neighbors through trial and error.
-
This last method use both decision trees and random forest to classify mushroom but also allow for a highly interperable model.

To see the coding Jupiter notebook and the paper or presentation, please scroll down to the bottom.
Exploratory data analysis
The dataset comes from the UCI Machine Learning Repository:
https://archive.ics.uci.edu/dataset/73/mushroom.
The data set contains 8124 hypothetic samples of 23 different mushroom species from the Agaricus and Lepiota Family.
There are 22 nominal categorical predictor variables and one binary outcome variable, making it highly applicable for one-hot encoding transformation.



Data preprocessing for modeling

Machine Learning Modeling:

Default Naive Bayes
-
Train accuracy: 95.68%
Test accuracy: 96.06%
Test precision: 93.42%

Optimize Naive Bayes
-
Train accuracy: 99.86%
Test accuracy: 99.51%
Test precision: 99.64%

Greedy Naive Bayes
-
Train accuracy: 99.69%
Test accuracy: 99.75%
Test precision: 99.53%
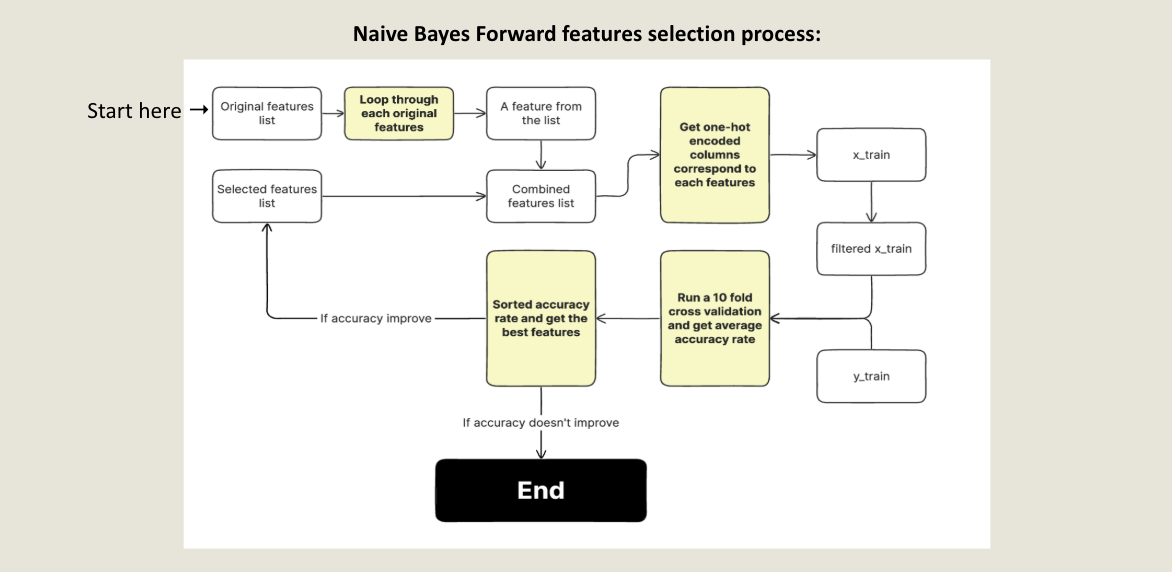
How to make Naive Bayes Greedy:
The making of a paradoxically yet powerful ML model for mushroom classification. Allowing for a highly compact & accurate model, rivaling random forest with the highest accuracy yet only needing 3/22 original variables.

KNN models, are a simple idea with powerful return.

-
Go through a loop from 1-100 #knn neighbour with cross validation to see the trend and to select the best one to prevent overfitting with high accuracy.
-
The best #K neighbour is where the gap between test and training is the smallest while having the highest possible accuracy. [~15 to 60].
-
Train Accuracy: 99.94%
Test Accuracy: 99.75%
Test Precision: 99.53%

-
Train accuracy: 98.89%
Test accuracy: 98.28%
Test precision: 99.63%
Decision Tree Model

-
Train accuracy: 99.94%
Test accuracy: 99.75%
Test precision: 99.53%
